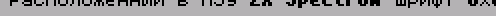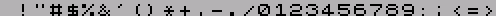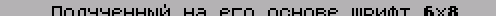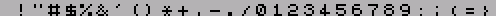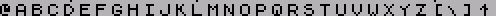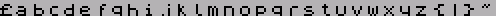|
Black Crow
#06
01 июня 2001 |
|
Программистам - Интересный алгоритм печати текста 42 символа в строке.

СЕКРЕТЫ ТЕКСТОВОГО ВЫВОДА (С) 2001 Иван Рощин Fido : 2:5О2О/689.53 ZЧNеt : SOO:95/462.53 E-uail: asder_ffc@softhoue.пет WWW : http://www.zx.ru/echo/roschin ----------------------------------------- Здесь я расскажу о приемах оптимиза- ции, используемых при выводе текстовых сообщений на экран ZX-Spectrum. Некоторые из этих приемов могут быть использованы и на других компьютерных платформах, где производится печать текста в графическом режиме. Сначала несколько общих слов. Как из- вестно, в ZX-Spectrum реализован единст- венный графический режим с разрешением 256*192. Цвета в нем задаются не для каж- дой точки, а сразу для целого квадрата 8*8 - то есть фактически мы имеем не нас- тоящее цветное изображение, а раскрашен- ное черно-белое. В других компьютерах (например, РС) наряду с графическими режимами обычно имеются и текстовые. Спектрум лишен этой возможности, и на нем приходится выводить текст в графическом режиме. С одной сто- роны, это медленнее и отнимает больше па- мяти, но с другой стороны - размеры, фор- ма и местоположение символов могут быть любыми. В графическом режиме также стано- вится возможным плавный скроллинг при просмотре текста, что несомненно повышает удобство чтения. Я буду рассматривать наиболее часто встречающийся случай, когда шрифт задан в растровом виде (бывают еще векторные шрифты), и все его символы имеют одинако- вую ширину и высоту. При печати может быть использован как шрифт 8*8, находящийся в ПЗУ по адресам #3D00-#ЗFFF (там хранятся лишь изображе- ния символов с кодами #20-#7F), так и шрифт, загружаемый в ОЗУ (размеры и коли- чество символов в котором, само собой, могут быть произвольными). Процедура печати символа обычно имеет дело с такими параметрами: код символа (byte), координаты (х,y) и цвет. Коорди- наты чаще всего задаются не в пикселах, а в знакоместах (под знакоместами я имею в виду области размером в один символ). Скажем, при использовании шрифта 8*8 на экране помещается 32 символа по горизон- тали и 24 по вертикали; соответственно, координата х может изменяться от 0 до 31, а y - от 0 до 23. Начало координат (0,0) традиционно располагается в верхнем левом углу экрана. Как видим, происходит некоторая эмуля- ция текстового режима с помощью графичес- кого. В 99% случаев при этом используется один из следующих трех "текстовых" режи- мов: 32*24 (шрифт 8*8), 42*24 (шрифт 6*8) и 64*24 (шрифт 4*8). (Как вы можете заме- тить, в режиме 42*24 четыре пиксела по горизонтали остаются неиспользованными - обычно их либо равномерно распределяют справа и слева, либо оставляют на какой- то одной стороне.) В режиме 32*24 каждый символ может иметь свой цвет (что непосредственно вы- текает из структуры спектрумовского экра- на). В режимах 42*24 и 64*24 это невоз- можно, но там каждое слово может быть ок- рашено в свой цвет (если считать, что слова разделены пробелами). Другие режимы (скажем, 51*24 - при использовании шрифта 5*8) лишены и этого. О теории я сказал, кажется, уже доста- точно. А теперь начнем оптимизировать! :) Обычно в шрифте под изображение каждо- го символа отводится восемь байт. Но до- вольно часто такое представление оказы- вается избыточным, так как некоторые биты не используются. К примеру, для шрифта 6*8 (рис. 1) два крайних столбца не за- действованы и всегда равны нулю.Рис. 1 Когда шрифт расположен в ОЗУ, такое его представление вполне оправданно, как обеспечивающее достаточную скорость печа- ти. (Между прочим, когда печать символов 6*8 хотят сделать особенно быстрой, ис- пользуют целых четыре набора символов, каждый из которых сдвинут относительно другого на два пиксела по горизонтали - чтобы не тратить время на сдвиг при печа- ти каждого символа.) Но для экономии дис- кового пространства, занимаемого вашей программой, имеет смысл удалять из шрифта всю избыточную информацию. Экономия при этом может быть весьма значительной: так, шрифт из 256 символов 6*8, изначально занимавший #800 байт, уменьшится на четверть. А если в таком шрифте изображение символов реально зани- мает только 5*6 пикселов (т.е. между сим- волами предусмотрен обязательный пробел в один пиксел по горизонтали и два по вертикали), то он сократится более чем вдвое! Ниже приведена процедура, удаляющая из шрифта избыточную информацию. Смысл ис- пользуемых в ней констант font_sx,font_х, font_sy и font_y пояснен на рис. 2.








 Рис. 2 SOURCE EQU #8000 ;здесь расположен ;исходный шрифт, DESTINY EQU #С000 ;а сюда поместим ;упакованный... KOLVO EQU #100 ;количество симво- ;лов (1-256) font_sx EQU 1;эти параметры опреде- ;ляют используемую часть font_sy EQU 1;матрицы 8*8 для преоб- ;разуемого шрифта font_х EQU 5 font_y EQU 6 DEST_LEN EQU ((font_х*font_y*KOLVO)+7)/8 ;длина упакованного шрифта ;в байтах ORG #6000 LD HL,SOURCE LD IX,DESTINY LD Е,0 LD В,KOLVO М1 PUSH ВС PUSH HL LD ВС,font_sy ADD HL,ВС LD В,font_y М7 LD A,(HL) LD С,font_sx INC С М2 DEC С JR Z,М3 ADD A,A JR М2 М3 LD С,font_х INC С М4 DEC С JR Z,М5 ADD A,A RL (IX) INC Е BIT 3,Е JR Z,М4 INC IX LD Е,0 JR М4 М5 INC HL DJNZ М7 РОР HL LD ВС,8 ADD HL,ВС РОР ВС DJNZ М1 DEC Е М6 INC Е RET Z BIT 3,Е RET NZ SLA (IX) JR М6 После загрузки программы с диска, ес- тественно, такой шрифт нужно будет преоб- разовать к его первоначальному виду. Вот соответствующая процедура (если заранее известно, какими будут значения констант, то ее можно оптимизировать): SOURCE EQU #8000 ;здесь расположен ;упакованный шрифт, DESTINY EQU #С000 ;а сюда будем рас- ;паковывать... KOLVO EQU #100 ;количество симво- ;лов (1-256) font_sx EQU 1 ;см. предыдущую проц. font_sy EQU 1 font_х EQU 5 font_y EQU 6 ORG #6000 LD HL,DESTINY PUSH HL LD DE,DESTINY+1 LD ВС,KOLVO*8-1 LD (HL),0 LDIR LD IX,SOURCE РОР HL LD Е,8 LD D,(IX) LD В,KOLVO М1 PUSH ВС PUSH HL LD ВС,font_sy ADD HL,ВС LD В,font_y М7 LD С,font_х XOR A М3 SLA D ADC A,A DEC Е JR NZ,М2 LD Е,8 INC IX LD D,(IX) М2 DEC С JR NZ,М3 LD С,8-(font_sx+font_х) INC С М4 DEC С JR Z,М5 ADD A,A JR М4 М5 LD (HL),A INC HL DJNZ М7 РОР HL LD ВС,8 ADD HL,ВС РОР ВС DJNZ М1 RET Впрочем, если вам необходимо экономить оперативную память, можно оставить шрифт и в сжатом виде, пожертвовав скоростью печати. Ну а чтобы скорость все-таки не очень пострадала, можно использовать еще несколько приемов оптимизации. Например, если печатается пробел, то быстрее будет просто очистить соответствующее знакомес- то на экране. При печати символа имеет смысл сначала восстановить его изображе- ние в специальном буфере и уже оттуда вы- водить на экран, учитывая при этом, что если печатается символ с тем же кодом, что и предыдущий, то его изображение уже сформировано в буфере (своеобразное кэши- рование). Проверка совпадения кодов сим- волов может быть реализована примерно так: ............... ;Печатаемый ;символ в ре- ;гистре A, СР 0 ;сравниваем ;его с кодом ;предыдущего LAST_S EQU $-1 ;символа (хра- ;нится в самой ;команде). JR Z,GO_PRN ;Если совпали, ;то выводим ;содержимое ;буфера, иначе LD (LAST_S),A ;запоминаем ;код символа и ............... ;формируем его ;изображение в ;буфере. GO_PRN ............... ;Вывод на эк- ;ран содержи- ;мого буфера. Еще один способ уменьшения размера шрифта, который может использоваться сов- местно с предыдущим - удаление из него неиспользуемых символов. Для этого можно воспользоваться такой процедурой: SOURCE EQU #8000 ;адрес исходного ;шрифта (256 симв.) DESTINY EQU #С000 ;адрес преобразо- ;ванного шрифта HIGH EQU 8 ;сколько байт зани- ;мает один символ ORG #6000 LD IX,ТАВ_DEL LD HL,SOURCE LD DE,DESTINY XOR A ;текущий символ NEXT_S PUSH AF CALL СНЕСК LD ВС,HIGH JR NZ,NO_LDIR LDIR ;обнуляет ВС NO_LDIR ADD HL,ВС РОР AF INC A JR NZ,NEXT_S RET ;Таблица удаляемых символов представлена ;в виде битового массива размером в 256 ;бит (32 байта). Если элемент массива ;равен единице, соответствующий символ ;будет удален из шрифта. ТАВ_DEL DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 ; Процедура СНЕСК предназначена для ; работы с битовыми массивами длиной ; до 256 элементов. ; ; Вход: IX - адрес массива; ; A - номер элемента. ; Выход: если соотв. элемент массива ; равен 0, флаг Z установлен. ; Значение A изменено. ; ; Если заменить команду BIT на SET или ; RES, можно не только проверять значения ; элементов массива, но и изменять их. СНЕСК PUSH AF ;сохранили номер эле- ;мента ; Работа с элементом массива происходит ; с помощью команды BIT N,(IX+S), которая ; перед этим формируется в памяти. ; Значения N и S вычисляются по формуле: ; S = старшие 5 битов номера элемента ; (номер байта в массиве, где находится ; нужный элемент); ; N = 8 - младшие 3 бита номера элемента ; (номер бита в байте массива; элементы ; располагаются в байте слева направо, ; а биты нумеруются наоборот). ; ; Команда занимает в памяти 4 байта и ; выглядит так:
Рис. 2 SOURCE EQU #8000 ;здесь расположен ;исходный шрифт, DESTINY EQU #С000 ;а сюда поместим ;упакованный... KOLVO EQU #100 ;количество симво- ;лов (1-256) font_sx EQU 1;эти параметры опреде- ;ляют используемую часть font_sy EQU 1;матрицы 8*8 для преоб- ;разуемого шрифта font_х EQU 5 font_y EQU 6 DEST_LEN EQU ((font_х*font_y*KOLVO)+7)/8 ;длина упакованного шрифта ;в байтах ORG #6000 LD HL,SOURCE LD IX,DESTINY LD Е,0 LD В,KOLVO М1 PUSH ВС PUSH HL LD ВС,font_sy ADD HL,ВС LD В,font_y М7 LD A,(HL) LD С,font_sx INC С М2 DEC С JR Z,М3 ADD A,A JR М2 М3 LD С,font_х INC С М4 DEC С JR Z,М5 ADD A,A RL (IX) INC Е BIT 3,Е JR Z,М4 INC IX LD Е,0 JR М4 М5 INC HL DJNZ М7 РОР HL LD ВС,8 ADD HL,ВС РОР ВС DJNZ М1 DEC Е М6 INC Е RET Z BIT 3,Е RET NZ SLA (IX) JR М6 После загрузки программы с диска, ес- тественно, такой шрифт нужно будет преоб- разовать к его первоначальному виду. Вот соответствующая процедура (если заранее известно, какими будут значения констант, то ее можно оптимизировать): SOURCE EQU #8000 ;здесь расположен ;упакованный шрифт, DESTINY EQU #С000 ;а сюда будем рас- ;паковывать... KOLVO EQU #100 ;количество симво- ;лов (1-256) font_sx EQU 1 ;см. предыдущую проц. font_sy EQU 1 font_х EQU 5 font_y EQU 6 ORG #6000 LD HL,DESTINY PUSH HL LD DE,DESTINY+1 LD ВС,KOLVO*8-1 LD (HL),0 LDIR LD IX,SOURCE РОР HL LD Е,8 LD D,(IX) LD В,KOLVO М1 PUSH ВС PUSH HL LD ВС,font_sy ADD HL,ВС LD В,font_y М7 LD С,font_х XOR A М3 SLA D ADC A,A DEC Е JR NZ,М2 LD Е,8 INC IX LD D,(IX) М2 DEC С JR NZ,М3 LD С,8-(font_sx+font_х) INC С М4 DEC С JR Z,М5 ADD A,A JR М4 М5 LD (HL),A INC HL DJNZ М7 РОР HL LD ВС,8 ADD HL,ВС РОР ВС DJNZ М1 RET Впрочем, если вам необходимо экономить оперативную память, можно оставить шрифт и в сжатом виде, пожертвовав скоростью печати. Ну а чтобы скорость все-таки не очень пострадала, можно использовать еще несколько приемов оптимизации. Например, если печатается пробел, то быстрее будет просто очистить соответствующее знакомес- то на экране. При печати символа имеет смысл сначала восстановить его изображе- ние в специальном буфере и уже оттуда вы- водить на экран, учитывая при этом, что если печатается символ с тем же кодом, что и предыдущий, то его изображение уже сформировано в буфере (своеобразное кэши- рование). Проверка совпадения кодов сим- волов может быть реализована примерно так: ............... ;Печатаемый ;символ в ре- ;гистре A, СР 0 ;сравниваем ;его с кодом ;предыдущего LAST_S EQU $-1 ;символа (хра- ;нится в самой ;команде). JR Z,GO_PRN ;Если совпали, ;то выводим ;содержимое ;буфера, иначе LD (LAST_S),A ;запоминаем ;код символа и ............... ;формируем его ;изображение в ;буфере. GO_PRN ............... ;Вывод на эк- ;ран содержи- ;мого буфера. Еще один способ уменьшения размера шрифта, который может использоваться сов- местно с предыдущим - удаление из него неиспользуемых символов. Для этого можно воспользоваться такой процедурой: SOURCE EQU #8000 ;адрес исходного ;шрифта (256 симв.) DESTINY EQU #С000 ;адрес преобразо- ;ванного шрифта HIGH EQU 8 ;сколько байт зани- ;мает один символ ORG #6000 LD IX,ТАВ_DEL LD HL,SOURCE LD DE,DESTINY XOR A ;текущий символ NEXT_S PUSH AF CALL СНЕСК LD ВС,HIGH JR NZ,NO_LDIR LDIR ;обнуляет ВС NO_LDIR ADD HL,ВС РОР AF INC A JR NZ,NEXT_S RET ;Таблица удаляемых символов представлена ;в виде битового массива размером в 256 ;бит (32 байта). Если элемент массива ;равен единице, соответствующий символ ;будет удален из шрифта. ТАВ_DEL DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 DB %00000000,%00000000 ; Процедура СНЕСК предназначена для ; работы с битовыми массивами длиной ; до 256 элементов. ; ; Вход: IX - адрес массива; ; A - номер элемента. ; Выход: если соотв. элемент массива ; равен 0, флаг Z установлен. ; Значение A изменено. ; ; Если заменить команду BIT на SET или ; RES, можно не только проверять значения ; элементов массива, но и изменять их. СНЕСК PUSH AF ;сохранили номер эле- ;мента ; Работа с элементом массива происходит ; с помощью команды BIT N,(IX+S), которая ; перед этим формируется в памяти. ; Значения N и S вычисляются по формуле: ; S = старшие 5 битов номера элемента ; (номер байта в массиве, где находится ; нужный элемент); ; N = 8 - младшие 3 бита номера элемента ; (номер бита в байте массива; элементы ; располагаются в байте слева направо, ; а биты нумеруются наоборот). ; ; Команда занимает в памяти 4 байта и ; выглядит так:



















 AND 7 RLCA RLCA RLCA XOR %01111110 ; %11111110 ;для SET, ; %10111110 ;для RES LD (СНЕСК_1+3),A РОР AF RRCA RRCA RRCA AND %00011111 LD (СНЕСК_1+2),A СНЕСК_1 BIT 0,(IX) RET Может быть и так, что вы сами не знае- те, печать каких символов производится в вашей программе, а каких - нет. В этом случае вставьте в процедуру печати симво- ла приведенный ниже фрагмент и запустите вашу программу. После окончания ее работы в битовом массиве ТАВ_DEL будут сведения о том, какие символы можно удалить из шрифта (в таком же формате, как и в пре- дыдущем примере). Логика работы такова: при каждом вызове процедуры печати симво- ла соответствующий бит в массиве обну- ляется, и в результате равными единице остаются лишь те элементы массива, кото- рые соответствуют символам, ни разу не печатавшимся за все время работы програм- мы. ; Начало процедуры печати: в аккумуляторе ; код печатаемого символа. PUSH AF PUSH IX LD IX,ТАВ_DEL CALL RES_BIT РОР IX РОР AF ............ ;продолжение про- ;цедуры печати RET ; Вспомогательная процедура, аналогичная ; рассмотренной выше процедуре СНЕСК: RES_BIT PUSH AF AND 7 RLCA RLCA RLCA XOR %10111110 LD (СНЕСК_1+3),A РОР AF RRCA RRCA RRCA AND %00011111 LD (СНЕСК_1+2),A СНЕСК_1 RES 0,(IX) RET ТАВ_DEL DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF При использовании такого шрифта возни- кают некоторые проблемы с печатью симво- ла, а именно - с вычислением смещения от начала шрифта, по которому находится изо- бражение данного символа. Тут можно либо использовать таблицу удаленных символов, либо перекодировать все текстовые сообще- ния, выводимые в программе. Чтобы еще уменьшить количество исполь- зуемых символов, можно заменить в выводи- мом тексте русские буквы на похожие по начертанию латинские. Вот соответствующая процедура: ТЕХТ EQU #8000;адрес начала текста LENGTH EQU #1234;длина текста ORG #6000 LD HL,ТЕХТ LD ВС,LENGTH М1 LD DE,TABLE-1 М2 INC DE LD A,(DE) INC DE AND A JR Z,М3 СР (HL) JR NZ,М2 LD A,(DE) LD (HL),A М3 INC HL DEC ВС LD A,В OR С JR NZ,М1 RET ;Пары символов - что на что заменять: TABLE DB "А","A" DB "В","В" DB "С","С" DB "Е","Е" DB "Н","Н" DB "К","К" DB "М","М" DB "О","О" DB "Р","Р" DB "Т","Т" DB "X","X" DB "а","а" DB "с","c" DB "е","е" DB "к","k" DB "п","n" DB "о","о" DB "р","р" DB "х","х" DB "у","y" DB 0 ;признак конца ;таблицы Нужно только следить, чтобы изображе- ния букв в используемом шрифте были дей- ствительно похожи. Если же, например, ла- тинские буквы в шрифте выполнены толще русских,то результат будет, как на рис.3:
AND 7 RLCA RLCA RLCA XOR %01111110 ; %11111110 ;для SET, ; %10111110 ;для RES LD (СНЕСК_1+3),A РОР AF RRCA RRCA RRCA AND %00011111 LD (СНЕСК_1+2),A СНЕСК_1 BIT 0,(IX) RET Может быть и так, что вы сами не знае- те, печать каких символов производится в вашей программе, а каких - нет. В этом случае вставьте в процедуру печати симво- ла приведенный ниже фрагмент и запустите вашу программу. После окончания ее работы в битовом массиве ТАВ_DEL будут сведения о том, какие символы можно удалить из шрифта (в таком же формате, как и в пре- дыдущем примере). Логика работы такова: при каждом вызове процедуры печати симво- ла соответствующий бит в массиве обну- ляется, и в результате равными единице остаются лишь те элементы массива, кото- рые соответствуют символам, ни разу не печатавшимся за все время работы програм- мы. ; Начало процедуры печати: в аккумуляторе ; код печатаемого символа. PUSH AF PUSH IX LD IX,ТАВ_DEL CALL RES_BIT РОР IX РОР AF ............ ;продолжение про- ;цедуры печати RET ; Вспомогательная процедура, аналогичная ; рассмотренной выше процедуре СНЕСК: RES_BIT PUSH AF AND 7 RLCA RLCA RLCA XOR %10111110 LD (СНЕСК_1+3),A РОР AF RRCA RRCA RRCA AND %00011111 LD (СНЕСК_1+2),A СНЕСК_1 RES 0,(IX) RET ТАВ_DEL DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF DB #FF,#FF,#FF,#FF При использовании такого шрифта возни- кают некоторые проблемы с печатью симво- ла, а именно - с вычислением смещения от начала шрифта, по которому находится изо- бражение данного символа. Тут можно либо использовать таблицу удаленных символов, либо перекодировать все текстовые сообще- ния, выводимые в программе. Чтобы еще уменьшить количество исполь- зуемых символов, можно заменить в выводи- мом тексте русские буквы на похожие по начертанию латинские. Вот соответствующая процедура: ТЕХТ EQU #8000;адрес начала текста LENGTH EQU #1234;длина текста ORG #6000 LD HL,ТЕХТ LD ВС,LENGTH М1 LD DE,TABLE-1 М2 INC DE LD A,(DE) INC DE AND A JR Z,М3 СР (HL) JR NZ,М2 LD A,(DE) LD (HL),A М3 INC HL DEC ВС LD A,В OR С JR NZ,М1 RET ;Пары символов - что на что заменять: TABLE DB "А","A" DB "В","В" DB "С","С" DB "Е","Е" DB "Н","Н" DB "К","К" DB "М","М" DB "О","О" DB "Р","Р" DB "Т","Т" DB "X","X" DB "а","а" DB "с","c" DB "е","е" DB "к","k" DB "п","n" DB "о","о" DB "р","р" DB "х","х" DB "у","y" DB 0 ;признак конца ;таблицы Нужно только следить, чтобы изображе- ния букв в используемом шрифте были дей- ствительно похожи. Если же, например, ла- тинские буквы в шрифте выполнены толще русских,то результат будет, как на рис.3:





 Рис. 3 Если в вашей программе используется шрифт 6*8, для экономии памяти можно фор- мировать образы символов с кодами 32-127 непосредственно во время печати, исполь- зуя шрифт ПЗУ. Вот пример небольшой прог- раммы, которая формирует таким способом шрифт и распечатывает на экране все полу- чившиеся символы. ORG #6000 LD HL,#3D00;адрес шрифта ПЗУ LD DE,#8000;здесь будет ;шрифт 6*8 LD ВС,#300 ;длина шрифта NEXT_В LD A,D ;Все символы раз- ;деляются на СР #82 ;две группы: JR Z,NO_IZM; 1) #2F-#5F СР #80 ; 2) #20-#2Е, ; #60-#7F JR NZ,IZM_1;Преобразование ;символов осу- LD A,Е ;ществляется по- ;разному, в зави- СР 15*8 ;симости от того, JR С,NO_IZM;к какой группе ;они принадлежат. IZM_1 LD A,(HL) ;Преобразование ;символов первой PUSH ВС ;группы PUSH AF AND %00001111 RLCA LD В,A РОР AF AND %11110000 OR В РОР ВС JR BYTE_ОК NO_IZM LD A,(HL) ; Преобразование BYTE_ОК RLCA ; второй группы AND %11111100 LD (DE),A INC HL INC DE DEC ВС LD A,В OR С JR NZ,NEXT_В ; Шрифт 6*8 подготовлен, теперь печатаем ; все полученные символы: LD HL,#8000-#100 LD (#5С36),HL CALL 3435 LD A,2 CALL 5633 LD A," " PRINT_S PUSH AF RST 16 РОР AF INC A СР 128 JR NZ,PRINT_S RET
Рис. 3 Если в вашей программе используется шрифт 6*8, для экономии памяти можно фор- мировать образы символов с кодами 32-127 непосредственно во время печати, исполь- зуя шрифт ПЗУ. Вот пример небольшой прог- раммы, которая формирует таким способом шрифт и распечатывает на экране все полу- чившиеся символы. ORG #6000 LD HL,#3D00;адрес шрифта ПЗУ LD DE,#8000;здесь будет ;шрифт 6*8 LD ВС,#300 ;длина шрифта NEXT_В LD A,D ;Все символы раз- ;деляются на СР #82 ;две группы: JR Z,NO_IZM; 1) #2F-#5F СР #80 ; 2) #20-#2Е, ; #60-#7F JR NZ,IZM_1;Преобразование ;символов осу- LD A,Е ;ществляется по- ;разному, в зави- СР 15*8 ;симости от того, JR С,NO_IZM;к какой группе ;они принадлежат. IZM_1 LD A,(HL) ;Преобразование ;символов первой PUSH ВС ;группы PUSH AF AND %00001111 RLCA LD В,A РОР AF AND %11110000 OR В РОР ВС JR BYTE_ОК NO_IZM LD A,(HL) ; Преобразование BYTE_ОК RLCA ; второй группы AND %11111100 LD (DE),A INC HL INC DE DEC ВС LD A,В OR С JR NZ,NEXT_В ; Шрифт 6*8 подготовлен, теперь печатаем ; все полученные символы: LD HL,#8000-#100 LD (#5С36),HL CALL 3435 LD A,2 CALL 5633 LD A," " PRINT_S PUSH AF RST 16 РОР AF INC A СР 128 JR NZ,PRINT_S RET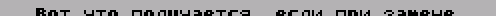
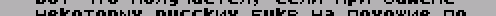
 Рис. 4 Между прочим, можно было бы применить этот способ в мониторе-отладчике STS - там как раз используется шрифт 6*8. А за счет освободившегося места можно было бы реализовать в этом отладчике какие-либо новые возможности... Теперь скажу несколько слов о спе- циальном способе хранения шрифта в памя- ти, при котором процедура печати оказы- вается более быстрой и короткой. Обычно в шрифте хранится сначала во- семь байт, образующих изображение первого символа, затем восемь байт второго симво- ла и так далее. При печати символа необходимо сначала (зная его код и адрес расположения в па- мяти шрифта) вычислить адрес, по которому находится первый байт изображения симво- ла, а затем по очереди читать байт изоб- ражения и записывать его в видеопамять. Пусть код символа задан в аккумулято- ре, адрес в видеопамяти (вычисляемый по координатам печати) задан в регистровой паре DE и известно, что шрифт расположен с адреса FONT. Тогда процедура печати бу- дет выглядеть примерно так: LD Н,0 ;Вычисление адреса LD L,A ;образа символа ADD HL,HL ;(10 байт/65 тактов) ADD HL,HL ADD HL,HL LD ВС,FONT ADD HL,ВС LD В,8 ;Вывод на экран. Для ;повышения скорости М1 LD A,(HL) ;цикл можно раскрыть LD (DE),A INC HL ;Если шрифт располо- ;жен с адреса, крат- INC D ;ного 8 - можно ;просто INC L DJNZ М1 RET "Да это все давно известно" - скажет кто-то. Не буду спорить. Обратите только внимание на то, сколько ресурсов тратится на вычисление адреса образа символа. А если высота символов будет не восемь пик- селов, а, скажем, семь? Тогда программа еще более усложнится, ведь уже не обой- дешься тремя сдвигами, как при умножении на восемь... Между тем, существует гораздо более эффективный способ хранения шрифта в па- мяти: шрифт начинается с адреса, кратного 256, в первых 256 байтах последовательно расположены верхние строки всех символов, в следующих 256 байтах - вторые сверху строки, и так далее. В этом случае, неза- висимо от высоты символов, вычисление ад- реса образа символа при печати практичес- ки не требует ресурсов. Вот пример проце- дуры печати символа: LD Н,FONT/256 ;Вычисление ад- ;реса образа LD L,A ;символа (3 бай- ;та/11 тактов) LD В,8 ;Вывод на экран. Для ;повышения скорости М1 LD A,(HL) ;цикл можно раскрыть LD (DE),A INC Н INC D DJNZ М1 RET Не правда ли, гораздо эффективнее? Но есть один недостаток: если в шрифте хра- нятся образы не всех 256 символов, то после преобразования он будет занимать больше места в памяти. (В общем случае размер будет равен Н*256 байт, где Н - высота символа.) Вот процедура, перекодирующая шрифт из обычного представления в более эффектив- ное: SOURCE EQU #8000 ;адрес расположения ;исходного шрифта DESTINY EQU #С000 ;здесь разместится ;преобразованный ;шрифт HIGH EQU 8 ;высота символов LD HL,SOURCE LD DE,DESTINY М1 PUSH DE LD В,HIGH М2 LD A,(HL) LD (DE),A INC HL INC D DJNZ М2 РОР DE INC Е JR NZ,М1 RET А вот процедура, выполняющая обратное преобразование: SOURCE EQU #8000 ;откуда DESTINY EQU #С000 ;куда HIGH EQU 8 ;высота символов LD HL,SOURCE LD DE,DESTINY М1 PUSH HL LD В,HIGH М2 LD A,(HL) LD (DE),A INC Н INC DE DJNZ М2 РОР HL INC L JR NZ,М1 RET Осталось только сказать, что, хотя та- кой способ хранения шрифта считается до- вольно известным, я до недавнего времени не предполагал о его существовании. А рассказал мне о нем GoBLiN/BMZ - спасибо!
Рис. 4 Между прочим, можно было бы применить этот способ в мониторе-отладчике STS - там как раз используется шрифт 6*8. А за счет освободившегося места можно было бы реализовать в этом отладчике какие-либо новые возможности... Теперь скажу несколько слов о спе- циальном способе хранения шрифта в памя- ти, при котором процедура печати оказы- вается более быстрой и короткой. Обычно в шрифте хранится сначала во- семь байт, образующих изображение первого символа, затем восемь байт второго симво- ла и так далее. При печати символа необходимо сначала (зная его код и адрес расположения в па- мяти шрифта) вычислить адрес, по которому находится первый байт изображения симво- ла, а затем по очереди читать байт изоб- ражения и записывать его в видеопамять. Пусть код символа задан в аккумулято- ре, адрес в видеопамяти (вычисляемый по координатам печати) задан в регистровой паре DE и известно, что шрифт расположен с адреса FONT. Тогда процедура печати бу- дет выглядеть примерно так: LD Н,0 ;Вычисление адреса LD L,A ;образа символа ADD HL,HL ;(10 байт/65 тактов) ADD HL,HL ADD HL,HL LD ВС,FONT ADD HL,ВС LD В,8 ;Вывод на экран. Для ;повышения скорости М1 LD A,(HL) ;цикл можно раскрыть LD (DE),A INC HL ;Если шрифт располо- ;жен с адреса, крат- INC D ;ного 8 - можно ;просто INC L DJNZ М1 RET "Да это все давно известно" - скажет кто-то. Не буду спорить. Обратите только внимание на то, сколько ресурсов тратится на вычисление адреса образа символа. А если высота символов будет не восемь пик- селов, а, скажем, семь? Тогда программа еще более усложнится, ведь уже не обой- дешься тремя сдвигами, как при умножении на восемь... Между тем, существует гораздо более эффективный способ хранения шрифта в па- мяти: шрифт начинается с адреса, кратного 256, в первых 256 байтах последовательно расположены верхние строки всех символов, в следующих 256 байтах - вторые сверху строки, и так далее. В этом случае, неза- висимо от высоты символов, вычисление ад- реса образа символа при печати практичес- ки не требует ресурсов. Вот пример проце- дуры печати символа: LD Н,FONT/256 ;Вычисление ад- ;реса образа LD L,A ;символа (3 бай- ;та/11 тактов) LD В,8 ;Вывод на экран. Для ;повышения скорости М1 LD A,(HL) ;цикл можно раскрыть LD (DE),A INC Н INC D DJNZ М1 RET Не правда ли, гораздо эффективнее? Но есть один недостаток: если в шрифте хра- нятся образы не всех 256 символов, то после преобразования он будет занимать больше места в памяти. (В общем случае размер будет равен Н*256 байт, где Н - высота символа.) Вот процедура, перекодирующая шрифт из обычного представления в более эффектив- ное: SOURCE EQU #8000 ;адрес расположения ;исходного шрифта DESTINY EQU #С000 ;здесь разместится ;преобразованный ;шрифт HIGH EQU 8 ;высота символов LD HL,SOURCE LD DE,DESTINY М1 PUSH DE LD В,HIGH М2 LD A,(HL) LD (DE),A INC HL INC D DJNZ М2 РОР DE INC Е JR NZ,М1 RET А вот процедура, выполняющая обратное преобразование: SOURCE EQU #8000 ;откуда DESTINY EQU #С000 ;куда HIGH EQU 8 ;высота символов LD HL,SOURCE LD DE,DESTINY М1 PUSH HL LD В,HIGH М2 LD A,(HL) LD (DE),A INC Н INC DE DJNZ М2 РОР HL INC L JR NZ,М1 RET Осталось только сказать, что, хотя та- кой способ хранения шрифта считается до- вольно известным, я до недавнего времени не предполагал о его существовании. А рассказал мне о нем GoBLiN/BMZ - спасибо!